
Getting an HTTP 403 Forbidden Error while scraping or crawling a website is one of the most common HTTP errors you will get.
There are often only two possible causes:
The URL you are trying to scrape is prohibited, and you need to be authorized to access it.
The website detects that you are a scraper and returns an HTTP 403 Forbidden Status Code as a forbidden page.
Most of the time it is the second cause, that is, the website is blocking your request because it thinks you are a scraper.
The 403 Forbidden error is common when you are trying to scrape a website that is protected by Cloudflare, as Cloudflare returns a 403 status code.
In this guide, we will walk you through how to debug the 403 Forbidden Error and provide solutions that you can implement.

Here are methods you can use to bypass the 403 Forbidden error without getting blocked.
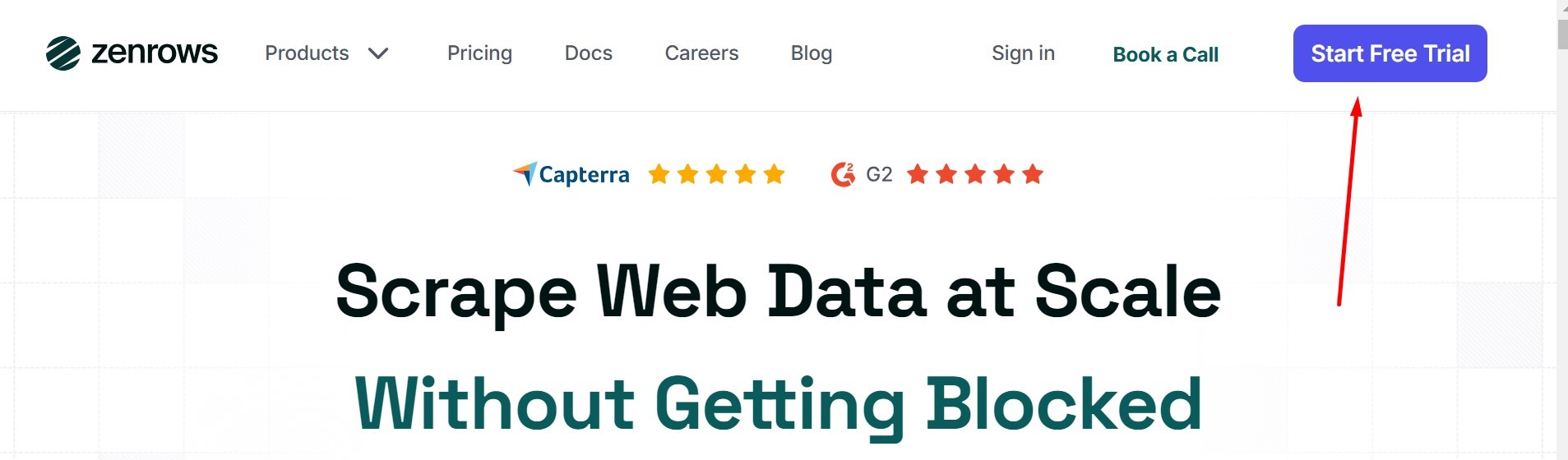
Use Web Scraping API from Zenrow
first open zenrow and Register on https://app.zenrows.com/register
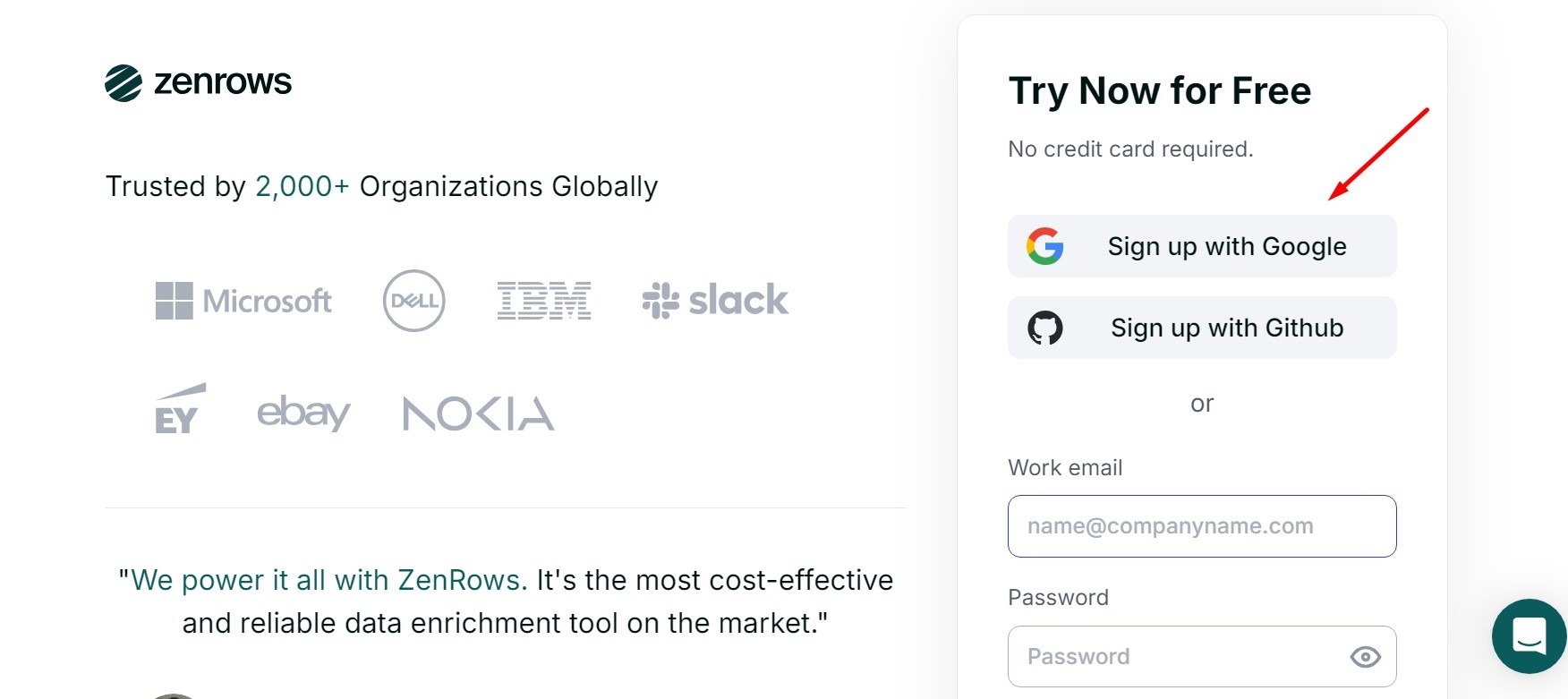
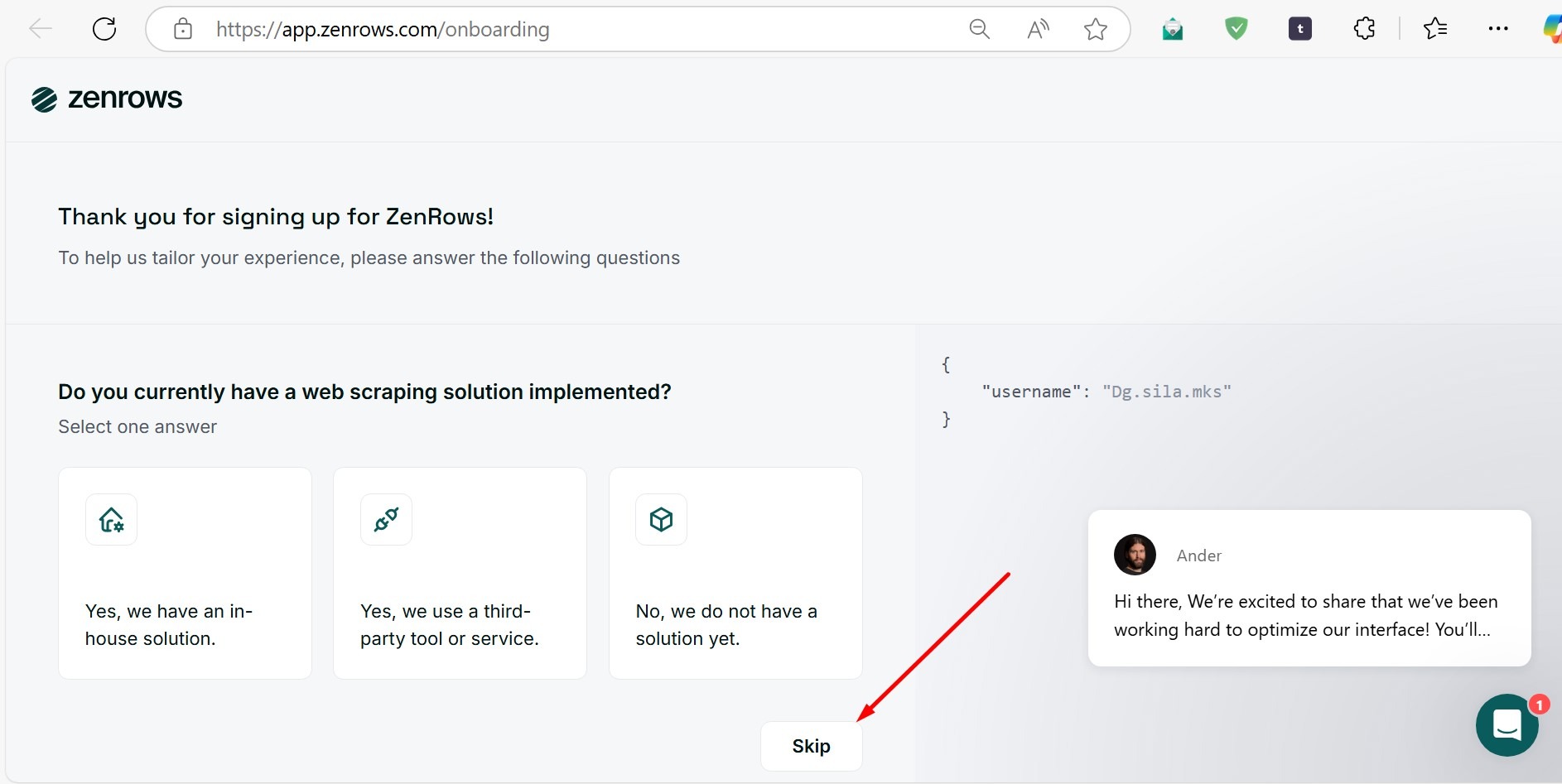
after you done, please check your email to get link and click verify your email address, after you verify… Click skip until you enter the dashboard page.
scroll until you find the api key, copy the api key and input to the zenrow api key column in the theme panel. done
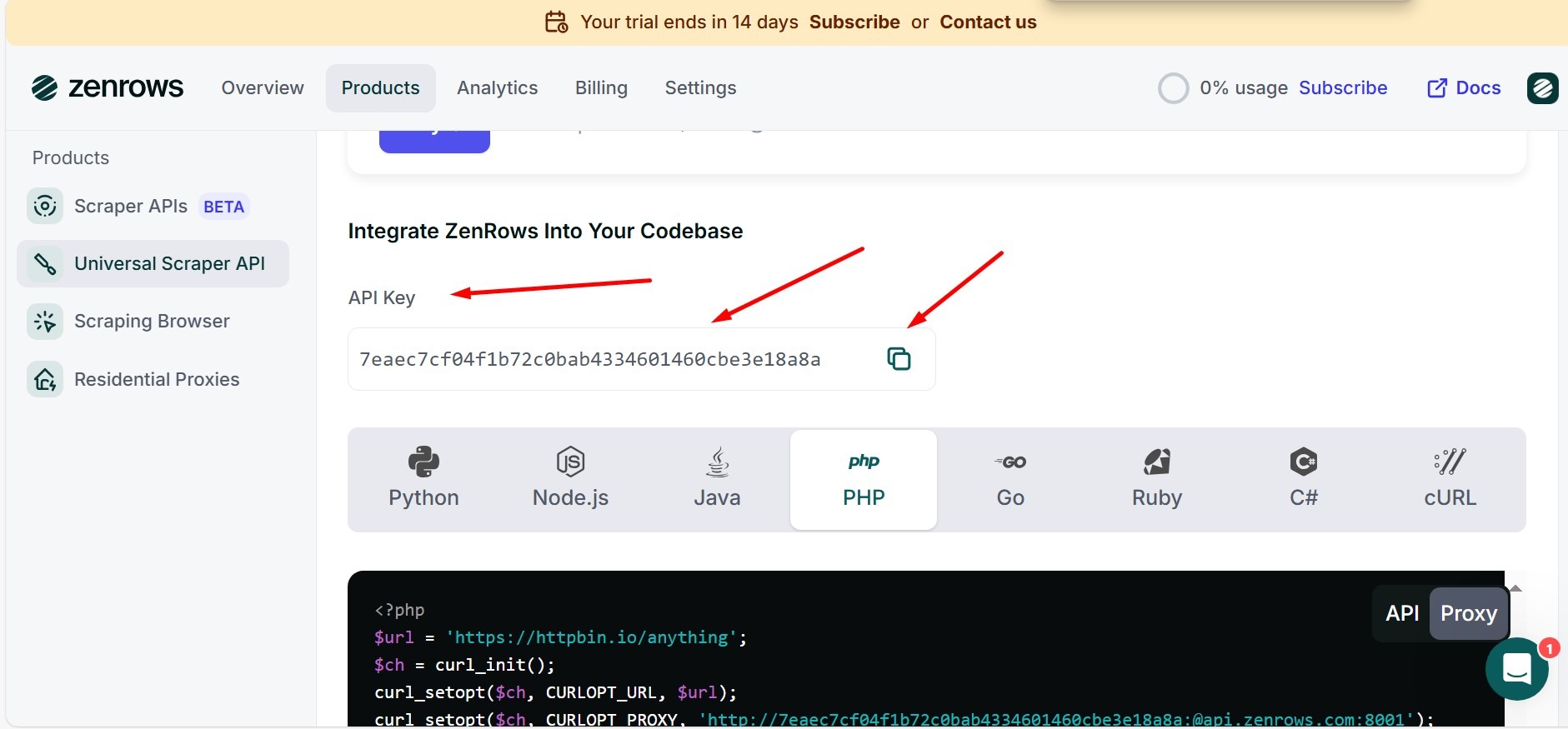
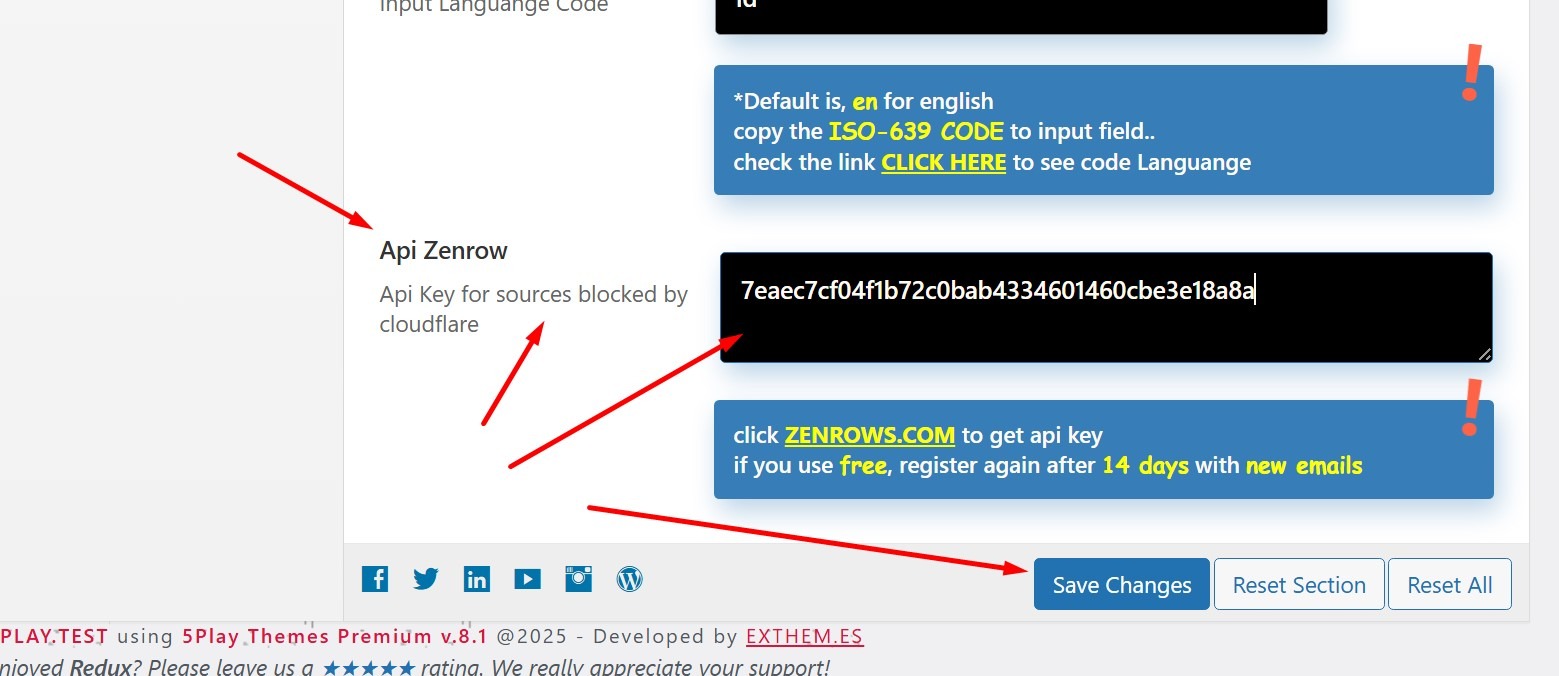
If you use a free API key, after 14 days or your limit has run out, you must re-register using a new email that has never been registered on Zenrow.

Note : zenrow trial ends only in 14 days
